


RPA从1.0到4.0,是对手、眼、脑和心的自动化,实现对数据搬移、识别、机器自动化管理和信任的建立,逐步替代初级和中级工作人员;与此同时,是帮助组织从提高现有业务的效率到创造新业务、实现开放生态互联的过程。
一开始我起的题目叫「白领工人保命指南」,意思是怎么用知识工程(知识工程是人工智能大分支之一,另外两个大分支是机器学习和神经网络。)这种技术,来帮助白领工人实现自动化工作——某种程度上也是“替代”他的工作。
过去这二十年时间里,我一直都在从事这种“邪恶”的研究——机器人流程自动化。
机器流程自动化时代:知识产业将由手工业走向大工业
知识产业,是用人产生知识,转移知识的产业,「白领工人」奋斗主战场。其中,金融是最典型的,此外还有专业服务、政务服务、传媒服务、教育服务等等。知识产业在经济中权重巨大,加在一起一共是占美国GDP的35%。美国的GDP里各种工业的占比是18%,知识产业在美国经济的比重是工业的两倍。
工业早就从手工业变成了大工业,但知识产业还没有完成这个转变,不管是教育、金融还是各种会计法律的服务,都像是一种手工业,依赖于个人的知识和人脉,而不是一种有体系可依赖的大型系统,所以知识产业可以说目前还没有完成工业化。
目前知识产业在美国是7万亿美元的规模,工业化一旦完成,我相信能够创造的价值是不止于此的。它所能够带来的价值和冲击,不夸张地说是大于200年前的工业革命的,这可能是我们当代最大的一个机会。
现在的知识产业是用人来产生知识和转移知识的,我们的愿景是未来用机器来产生知识、转移知识。

知识产业的自动化,就需要用到知识技术,这也是非常庞大的一个技术体系。当然笼统来讲,知识技术可以分为两大类技术,一类是产生知识的技术,一类是转移知识的技术,今天整个话题都是围绕着这两大类技术来展开的。
想要深刻理解RPA,就得明白流程自动化处理的「知识」是什么。小到一次报税,大到各机构间的合作,蕴藏着知识产业各阶段的需求和知识技术的发展轨迹。
在计算机科学里,知识就是结构(structure),或者说它是事物(thing)之间的联系(relation)。比如亲属关系,比如说爸爸的爸爸是爷爷,是普适性的知识。我们身边所有的事物之间的关系本质上都是知识。比如一张发票,它的表格的框就是结构,所以我们遇到的每一张发票其实都是一个知识库。
并非只有文本类才算知识,只要能够事物之间产生关系的,它都是知识。
例如宝马汽车的自动车库系统,车子靠近车库时,车库门会自动打开——车子和车库这种靠近关系,本身就构成了一个结构,这也是知识,也会产生事件。稍后我们会看到,这也是流程自动化的一个重要组成部分。
过去一年,我们听到RPA这个词,但并不意味着流程自动化是最近一年才出现,它很久以前就已经出现,只是不叫这个名字。
RPA 1.0阶段:自动化手
RPA的前身:RSS和IFTTT
流程自动化技术其实在很久以前就有了,1.0 版本主要是自动化手。
在十五到二十年前,新闻自动化推送技术叫mash up。当年社交网络刚刚兴起,每个社交网络都会有一些API(应用编程接口),有人就想怎么把这两种不同的应用串起来,或者把不同应用的数据源用机器自动串起来自动分发。RSS就是其中用于新闻的自动分发的一个技术。
与此相关的,还有另一种类型的应用:美国的IFTTT网站(if this then that)。
如果你有个to do list,要在你的亚马逊音箱上面来提醒你,做同步;或者你喜欢了一个spotify播放列表,要从video里面把歌曲剥离出来,这些自动化的任务,由一个触发器然后导致一个预定的动作,这就是if this then that。
IFTTT刚刚被发明出来的时候,更多的是这种任务:比如一条推特一旦满足关键词需求,就自动转发到Facebook。其实这也是一种to C的流程自动化。
To B的也有很多,比如历史上很有名的IBM Clio项目,1999年就开始了。因为企业内部有很多数据壁垒,有很多不同的内部IT系统,系统背后又都有不同的数据库。要想把这些数据库打通,是很麻烦的。
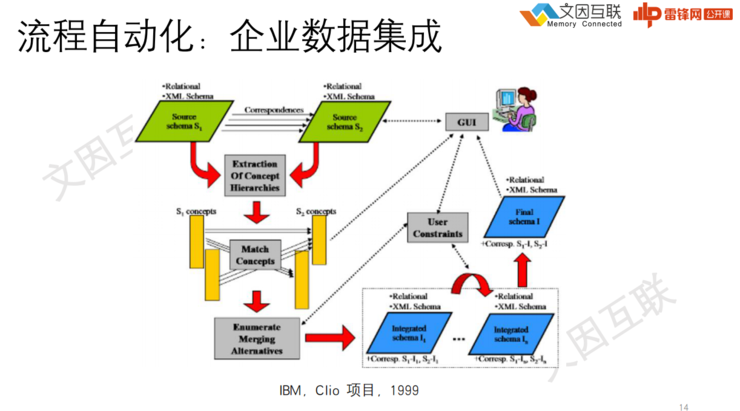
所以IBM就起了这么一个项目:怎么能够把不同数据库之间的数据模式做自动发现对齐,之后用统一数据查询,实现多数据源的数据集成自动化,最终实现任务自动化——这个问题,到今天也没有完全被解决掉。
刚才介绍了知识和流程自动化这两个核心概念,他们之间的关系是什么?如果我们想有流程的自动化,就必须拥有机器可读的结构化数据,即知识。然后才能用机器或者软件代理来自动化执行任务。
这也是狭义RPA。
UiPath这样的RPA公司,在美国刚开始的时候其实就是做软件代理的自动化任务执行。
RPA 1.0阶段应用举例:报税单自动填写
在美国报税,代发工资的公司ADP在每年年初会给寄工资单W-2,列明去年的收入、各项税额等。税表里的数据要挪到美国税务局给的一张个人报税表(1040),再把这个表导到各种报税软件,如TurboTax。人就需要做这样一个应用间的数据转移。

之前都是我们自己,或者雇个会计帮你做,这就是用手来做应用间的数据的转移。现在可以用RPA机器人来做。
在企业环境下,这件事也很重要,因为企业内部有很多不同的IT系统都需要被打通,比如说CRM系统和内部ERP系统怎么对接资源?它们可能都是不同厂商实现的,所以就需要用一些自动化的数据扒取技术来实现。
这个技术并不是全新的,其实之前在很多其他地方已经出现过了,比如90年代末的游戏外挂,后来有了更加先进的软件如按键精灵等。
互联网公司的测试团队也在做类似的事情,比如说开发网站,要测试所有使用路径是否正常,达到预期结果。但这过程很复杂麻烦,可能要测试几百个不同的路径。
一般软件的测试,只要把一些use case写进代码里,但是像这种Web的软件测试要在浏览器里运行,要从浏览器的页面里面把数据抓出来、填进去,所以最早为了解决这种外部的自动测试问题,就开发了一系列的技术。
这里面引用的是Selenium,一个很常用的外部自动化测试框架。如果你要做一个user login,写很少一段的Python代码就可以做这件事情。
同样地,你也可以分析页面,可以读取、抓取、填写数据。所以你会看到自动测试的软件跑起来的时候,这台机器就好像着了魔一样,鼠标乱飞,一些数据自动就被填进去了。
现在的RPA技术其实就是从自动化测试技术衍生出来的,这就是RPA的1.0时代:如何去自动在不同的应用之间做数据的转移,这个应用可能是windows上的桌面程序,也有可能是浏览器里的互联网Web程序。
RPA 2.0阶段:自动化眼
近两年,RPA开始进入第二阶段。
之前的1.0阶段,所要移动的数据基本是现有的结构化数据,比如在两个网页之间传数据,数据已经被结构化了,只是它呈现的是所谓的网页结构,或将已有的可读XML、电子表格,转到另外一个程序里。
但如果是PDF这种比较复杂的大量表格,或者新闻,招股说明书、债券募集说明书、信贷文件等,以及格式不复杂但内容很复杂,比如法院判决书,你要能够在这里面进行应用之间的数据转移,这就需要知识提取的技术。
简而言之,RPA 1.0时代,可以移动原有的结构化数据——RPA 2.0时代,可以生产结构化数据,移动非结构化数据,这就是核心的区别。
这个过程,其实之前是咱们用实习生——或者叫小弟小妹科技——用一些比较初级的工作人员来做的。流程自动化之后,RPA 1.0、2.0可以替代初级人员,这也是所谓的“加工已知的已知”:原来文件和表格有哪些数据,我们非常忠实地把这些字符串给迁移过去。

上图左边的文本原文讲到一个公司有信用危机,这就需要提取核心内容,比如公司出现的问题,它跟其他相关联的所谓实体,如上游公司、子公司,或者打官司的对手公司有什么关系?这样就从一个非结构化的文本变成了结构化的三元组数据。
这也是我们过去这几年之间为用户做得最多的事情。我们跟证券交易所、一些银行一直都在做这种金融监管、信贷、资产管理领域中大量的文件自动化处理,以前要几个月时间才能处理完的招股说明书,现在10秒钟之内就可以自动把几百页的内容都提取出来。
RPA 3.0 阶段:自动化脑
在这个阶段,就不仅仅是把数据原样加工和转移,而是自动化业务知识。
比如金融监管有合规的需求,交易所的合规文件非常多。要把里面所包含的业务知识,转化成机器可以执行的业务规则,这不仅需要识别数据本身,而要知道数据背后隐藏的内容,以及通过这些数据可推理出的结果。
所以,关键过程是如何让机器挖掘这些关系,和自动化的管理。从这个意义上来讲,RPA 3.0就是自动化脑的过程。一旦完成这一步,能够替代的不仅仅是初级人员,还有一些中级人员。
这里两大核心技术,一是知识图谱技术,另一个是推理机技术。
知识图谱
知识图谱的技术,本质上来说,就是说如何发现未知的已知。有了数据,可以推理出背后隐藏的关系。
比如说张三是李四的哥哥,李四是王五的哥哥,可以推理出来,张三是王五的哥哥,因为这是一个传递关系。这就是如何通过已知,发现未知的已知。
当然在To B的应用里,有更加专业的各种关系:比如通过各种隐藏的股权关系和已知的担保关系,发现未知的担保关系,可以通过股权网络发现不同公司间的集团派系;甚至还可以发现要隐藏的一致行动人关系,比如两个人关系很密切,他注册了好几个公司都在同一个地址里面,这两个人可能潜在有非常强的相互关联关系。
通过这些关系,可以发现很多隐藏的风险,这就是知识图谱技术能够帮助我们做到的——读懂数据不仅仅只是看到字面上的东西,而且还看到背后隐藏的关系。
但有时候知识图谱技术不够用。当我们有了更加深刻的知识,比如说财务的勾稽关系、大量的BPM管理知识,这需要用更加复杂的知识管理技术,各种各样的规则系统。
如果规则很少,只有十几条,其实用什么系统都无所谓,随便找一个本科毕业生都可以搞得定。但当你有几百条规则,再用规则编辑器,就很难管理了。当规则有一千条,一般的团队基本已经不能胜任这种任务。
通常做一个问答系统,既需要深度学习或自然语言处理的能力,也需要规则的能力。一般来说,管理1000条规则已经很复杂了,这个系统就已经看起来很聪明。但是还不够,如果想让系统看起来非常地鲁棒和聪明,通常需要1万条左右的规则。
比如说IBM的Watson系统,它的前面写了大概8000条的规则——如果想搞定这1万条规则,需要“灭霸级”的能力,这是绝大多数的团队是不具备的。
推理机技术
如何管理大量规则?需要引入知识库管理系统,推理机是最核心的一环,通过大量的规则,找到合理的结果并解释。
这事的逻辑很简单,但为什么在工程上非常困难?因为不可能找到一个自洽的逻辑系统,不同的人写出的业务规则肯定会打架,如果推理机不能消解这种冲突,在现实中肯定没用。
另外,也不可能把全部的知识库都给结构化或者规则化,很多是半结构化的。怎么把结构化和半结构化的知识整合在一起使用,降低总拥有成本,这也非常复杂。
最后推理出来一个结果,还要解释它,比如法律判案、医疗诊断,都是基于大量的业务知识,不能说“系统它告诉我就是这样,我也不知道是为什么”。比如判案,肯定是根据某一条结果、某一个法律,这就是叫可解释的人工智能系统,这是跟深度学习非常不一样的地方。
所以演绎的能力、消解冲突的能力、结果的解释能力加在一起,其实就是推理机最核心的几个模块。
当然还有很多其他的模块,比如推理加速。有了这些之后,我们就可以让机器学会自动管理,从而让大规模业务知识的执行自动化,来实现辅助中级业务人员的能力。
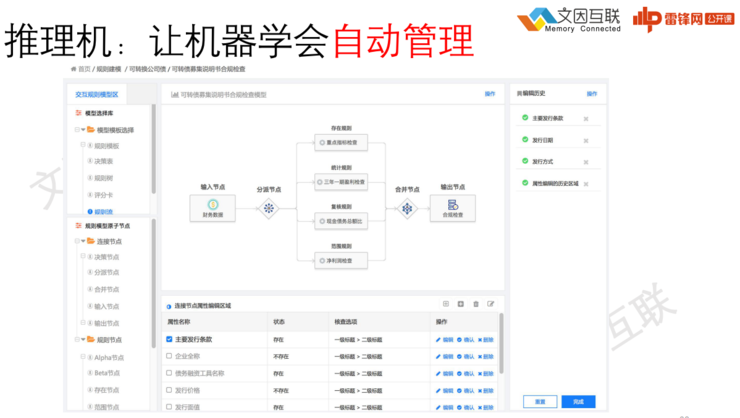
案例:债券合规的自动化检测和完整性检查
银行间协会的债券发行合规文件非常多,所以要构造出大量这样的业务规则系统,每个节点上面都会读取相应的数据,从而完成整个合规的检查过程。
案例:上市公司公告
先提取公告,检查是否含违规内容,比如发行时间,业绩预测符合此前预测,重大合同是否满足披露准则等等。
上市公司公告有多少种?400种。IPO审核后要看多少个数据点?7000个。这些全部用人工来做,肯定做不完,所以一定要用机器来做。
一个监管系统里面可以跑2500条规则,基于这些规则自动做数据路由、分析、统计,最后生成各种预警,发送给相应的人,生成各种各样的报表。这是一个非常复杂的业务流程,只有RPA 3.0时代的系统才能够胜任。如果只有手工的规则编辑器,很难去满足这样的需求。
展望一下,其实RPA到了这个阶段,以后要做的就不只是自动化一些简单流程,实际上是要把企业的业务自动化,或者企业有BPM、ERP、PLM、CRM系统……企业内部各种不同的资源都会有一个管理系统,这些管理系统现在背后都是数据库,未来则会是基于知识库来进行企业资源的调度。

例如CRM系统以前都是用关系数据库,现在越来越多用到图数据库,BPM、SEM、供应链系统也是一样。越来越多图谱的数据,有越来越多的规则,和数据规则知识库,怎么把这些整合在一起?就变成了知识库管理系统。
知识库再加上推理机,我认为这可能是下一代的RPA系统最核心的技术,就是怎么构造出一个能够通用于所有IT系统底层的知识库管理系统。我相信,它会替代之前类似Oracle这样的数据库管理系统的地位。
RPA 4.0阶段:自动化心(信任)
组织内是完全信任的环境,而组织间是不完全信任环境,
前三个阶段一直在讲,组织内部如何实现业务知识的产生自动化和转移自动化。显然,自动化不会仅仅只限于组织内部。
如果要在两个组织之间构造出这样一个自动化系统,面临的核心挑战是:组织内是完全信任的环境,而组织间是不被完全信任的。
在组织间建立自动化信任机制,我们称为分布式信任技术。
为什么要用这种技术?以开放银行为例,未来的银行其实是一堆API组合在一起的数据服务,但要想构造出这样的分布式应用,就必须建立起一个高度可信的工作环境。
有了这种分布式信任能力,就进入了RPA的第4个阶段——自动化心,这也代表人和人之间的信任。
说到分布式信任,大家肯定想到区块链,其实它只是可追责性技术的一个分支。
此外,分布式信任还包括了信任度的电子化,比如说电子身份、电子合同、电子发票等等,也包括了开放调度系统技术,还有服务的发现和注册、服务的编排和集成,分发引擎等等……这些技术在十几年前叫web service。
可追责性(accountability)技术
这个概念由图灵奖得主Tim Berners-Lee提出。
构造一个大规模的协作系统,很难事先阻止所有不轨行为。如果完全阻止,系统就非常没有活力。只能是给每个人设定做事的合理范围,如果做错,产生不良后果,我们可以找你负责,这就叫事后追责。
这个技术需要以下环节:
忠实记录数据处理和传播的过程。这个现在是用区块链来实现。十几年前还没有区块链,Tim的实验室发明了一整套跟区块链并行的技术来做。当时我也参与了这个工作。现在其实两个技术已经融合了。
拥有现场记录后,还要取一手证据。如果发现问题,要一步一步重建犯罪现场,需要溯源图谱技术(provenance)。
发现了问题也收集到了证据,必须建立起支撑结论的证据充分的完整链条,这就是证据推理技术(proof&justification)
以上环节加在一起,才是完整的可追责能力,这也是对现在区块链的重要补充。
Tim Berners-Lee过去十几年时间一直在促进这种技术的成熟;这两年在开发SOLID框架,这是基于分布式的去中心化应用,可以是结合知识图谱和区块链构造一种可追责的分布式任务自动化系统。
总结一下核心五大类技术:
顶层技术:产生知识,转移知识。
产生知识分为:如何发现事物(知识提取技术),如何发现关系(知识图谱技术)。
转移知识分为:组织内、组织间转移知识的技术。
组织内分为:自动化测试技术或RPA 1.0的技术,推理机技术。
组织间转移知识的技术,就是分布式信任的基础。
从RPA的四个阶段来总结:
1.0:自动化手,基于自动化测试技术,从而实现数据搬移。
2.0:自动化眼,实现数据识别——1.0和2.0结合,实现了对初级人员工作的替代。
3.0:自动化脑,基于知识图谱和推理机技术,帮助我们进行机器自动化管理。
4.0:自动化心(信任建立),加上3.0就是对中级人员的替代。
从另一个角度来划分,前三个阶段主要关注内部自动化调度;最后阶段关注外部自动化调度。
文因互联当前是关注在2.0和3.0。过去三年,我们一直围绕着RPA 2.0的技术,在做各种金融文档的自动化识别和流程自动化。最近逐渐转移到RPA 3.0的开发,即如何自动化脑、大规模批量产生成千上万条规则和批量管理。
RPA 4.0,如何实现组织间的自动化调度系统,这也是我们今后两三年内最重要的一件事情。
最后也给出我的两条建议:要么参与这一场自动化的革命,从被机器取代转为与机器协作;要么调整自己的方向,往未知的未知深耕,去发挥自己的创造力。
Q&A节选
问:关于分布式信用平台,是不是和联邦学习的联合建模异曲同工?
鲍捷:基于我的理解,联邦学习应该是每一个不同的数据源,需要保护自身隐私,然后再自动化、相当于去隐私的环境下,来进行一个集成的学习。
这个跟分布式信任应该是在做不同的事情。分布式信任解决的是我如何信任一个数据;联邦学习解决的是我如何在不破坏隐私的情况下实现学习。这两个应该是互补的技术。当然除了联邦学习技术,我认为同态加密技术也是很重要的。
问:RPA感觉是NLP在推荐搜索更进一步的应用,比搜索推荐要难,搜索推荐的本质还是关键词匹配,talk的API就不止关键词匹配了,要怎么理解文本中的实体和关系?
鲍捷:其实核心就在于传统的NLP阶段,我们要处理的都是字符串,要在字符串之间做一些对应关系。
而在所谓的图谱阶段,我们所要处理的都是实体,每一个实体都是有UUID的,比如说全国有多少个叫“王伟”的人,“王伟”是一个字符串,但是我们想区别不同的“王伟”,就需要给他UUID,这就是变成了实体。
所以说在做实体的时候,我们要做的就不是关键词匹配了,RPA其实从整体上来说还是做实体的匹配。
问:NLP这些算法并不能达到百分之百成功的效果。如果是流程自动化,对结果的准确度要求应该挺高的,想知道实际中如何平衡这种技术的局限性和业务的需求?
鲍捷:第一种方法,你这个系统如果要严格一点,你可以降低recall,但是你提取出来给我的数据,你要保证这个是正确的,可以用precision 和recall之间做一个交换。
另一种办法就是人工加机器,这个机器先做一轮,然后人工审阅一轮。这也是绝大多数实施成功的案例里面最终用的方法,就是人工加上机器做一段初步的分析,再用校验人员来做后面的数据提升,特别是补漏。
其实还有其他的平衡,比如说如果一部分确实是正确度不高的话,始终都不高,这部分可能我们就不追求它的自动化了,放弃本身也是一种很好的做法。
本文是51RPA中文社区原创文章。发布者:RPA小当家,转载请注明出处:https://www.51rpa.net/rpanews/7392.html