
最近有一条新闻,说是由于用户大量使用RPA报税机器人,这些RPA报税机器人使用暴力破解验证码和网络爬虫的方式,大量占用带宽,严重影响这些系统的稳定性和安全性。如下图:


河北省电子税务局官网公告原文如下:
河北省电子税务局指出,根据省局对电子税务局近期流量监控的情况显示,发现报税机器人采用”网络爬虫技术“或破解验证码等方式,对河北省电子税务局进行极为频繁地模拟登录、模拟申报等操作。不但极大地霸占了正常带宽,严重地影响了电子税务局系统的稳定性和安全性,而且未经河北省税务局许可即在开展批量报税业务,可能产生申报数据错误,存在企业数据安全泄露的风险,并进一步影响全省的税收征管数据质量。
鉴于非法的报税机器人和破解验证码批量模拟登录申报等业务可能给全省纳税人正常申报纳税造成的严重影响,为了还大家一个稳定的申报环境,通知如下:
一、严禁任何纳税人或代理机构以任何理由任何方式使用报税机器人或破解验证码方式进行批量申报缴税,对于使用报税机器人情况,省局会密切监控,发现异常会及时采取必要的措施,保障电子税务局平稳正常运行!
二、对于使用报税机器人而对电子税务局正常运行造成严重事故、影响正常征收秩序的,河北省税务局将依法追究相应人员或机构的法律责任。
三、报税机器人申报产生的错误申报数据等,影响到企业纳税信用等级评价结果,由企业或机构自行承担!
RPA报税机器人的出现,主要是解决大量人工重复劳动,解放双手,听起来是一件很美好的事情。凡事有利就有弊,对于用户来说,解放了双手,但对于税务系统来说,就变成很有压力的一件事情。RPA报税机器人本质就是利用网络爬虫技术对网站进行操作,爬虫技术之所以会被识别并容易通过技术方式被禁,因为它的操作区别于人工正常的操作。 试想如果大家都写网络爬虫,各种不规范的网络爬虫对系统的异常访问容易导致服务器系统的错误。另外对报税用户来说,网络爬虫的请求的方式、格式有别于正常的手工操作,容易通过技术手段来屏蔽,让机器人失效。
如果机器人能够完全模拟人工的手工操作,使用真实浏览器,就不会对服务器有影响,让你解放双手的同时也不给政府添堵。通过一定的RPA技术,我们就能够实现这一点,让机器人模拟的跟人工操作一样。
下面我就用开源技术框架Puppeteer来为你演示 如何操作Chrome,做到机器人模拟的像是一个真人在操作似的。
先来简单介绍一下Puppeteer:
Puppeteer是Chrome团队开源的Node库,其提供基于DevTools协议的高阶API让开发人员能够操作真实的Chrome浏览器,实现精细的操作。
通过Puppeteer能够将平时手动使用浏览器的操作通过代码的方式自动化执行,例如抓取网页、填充表单、下载文件、自动化测试,甚至使用开发者工具等。
以微博网站为例,来写一个自动化发微博的RPA。
这里为了驱动RPA,我们使用了LeanRunner RPA工具,它除了提供内置的自动化库以外,还能方便的调用各种开源自动化库,实现多端自动化。另外,它使用了行为驱动的框架,执行步骤用自然语言描述,提高了脚本的可读性。
1、描述业务流程
定义RPA的业务流程。
开LeanRunner脚本编辑器,在【工具箱】–【框架】拖拽相关函数。
添加场景:拖拽场景函数。
添加步骤:拖拽步骤函数。
定义完成后生成代码样例。
const { step, stepGroup } = require('leanrunner');
async function main() {
await stepGroup("自动发微博RPA", async () => {
await step("打开微博官网登录用户", async (world) => {
})
await step("处理登录验证码", async (world) => {
})
await step("发布微博内容", async (world) => {
})
})
}
Workflow.run(main)业务流程的定义无需了解自动化技术,普通的业务人员就可以完成。
2、实现业务步骤
当业务流程定义后,技术人员可以上场了,将每个业务步骤实现为代码。在框架代码中实现具体操作。
参考Puppeteer API,完善对应的代码:
const { askInput, Workflow, step, stepGroup } = require('leanrunner');
const puppeteer = require('puppeteer')
const { username, password } = require('./config')
async function main() {
await stepGroup("自动发微博RPA", async () => {
let broswer = await puppeteer.launch({ headless: false, slowMo: 200, defaultViewport: { width: 1200, height: 700 } })
let page = await broswer.newPage();
await step("打开微博官网登录用户", async (world) => {
await page.goto("https://weibo.com/")
let user_input = await page.waitForSelector('input[id="loginname"]')
let passwd_input = await page.waitForSelector('input[type="password"]')
await user_input.type(username)
await passwd_input.type(password)
await page.click('a[action-type="btn_submit"]');
})
await step("处理登录验证码", async (world) => {
const ele = await page.waitForSelector('input[node-type="verifycode"]')
const isdisabled = await (await ele.getProperty("disabled")).jsonValue()
if (!isdisabled) {
const verifycode = await page.waitForSelector('[action-type="btn_change_verifycode"]');
const imageBuffer = await verifycode.screenshot({encoding:'base64'})
let text = await askInput({
"message": "图片验证码",
"base64Image": imageBuffer,
"waitSeconds": 10000
})
await ele.type(text);
await page.click('a[action-type="btn_submit"]');
}
})
await step("发布微博内容", async (world) => {
const textarea = await page.waitForSelector('textarea[title="微博输入框"]');
await textarea.type('xxxxxxxxx')
})
})
}
Workflow.run(main)代码讲解
- 前文提到要让机器人像真人一样, 主要是通过
slowMo: 200参数来控制Puppeteer的操作动作之间的行为操作。相当于每个字符输入间隔200毫秒,这个可以根据真实的人工操作特征设定。 - 在处理微博验证码问题上,验证码的出现不是固定的,解决方法就是根据页面元素变化,如果验证码出现,就处理验证码,验证码没有出现,就不用管了。
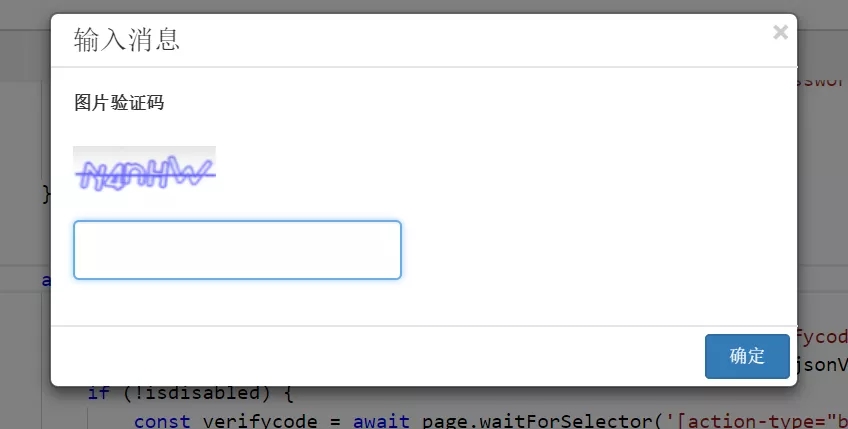
- 当验证码出现的时候,一方面可以调用公网的OCR服务来识别,也可以用LeanRunner自带的OCR库(免费、离线调用等优点),如果这两种验证码识别技术都不能解决,还可以使用LeanRunner自带的人工识别的方式,相当于是有人值守的RPA。本次示例代码用的就是人工识别的方式。在调试运行过程中将图片信息传递到设计器中,让人工识别验证。如果是在生产环境中运行,就是显示在web端的控制器中。
最后,使用LeanRunner 编写的RPA任务上传到 服务器端,可以定时运行,并生成运行结果报告。
总结
在这个例子中,您使用免费开源的Puppeteer,驱动真实的浏览器,并以人工操作的方式和速度访问网站,与真人操作几乎没有不同,对服务器而言,也觉察不到这是机器人在访问,最大限度的减少了对服务器的干扰和压力。
同时我们使用了LeanRunner RPA自动化工具。使用自然语言描述业务流程,并实现代码。这种行为驱动的开发模式让业务人员和技术人员可以保持良好的沟通。同时它支持无人值守和有人值守两种模式,使用方式灵活。通过这种开源框架结合产品的方式,让自动化脚本有良好的可控性和可维护性,保持灵活性的同时也降低了成本。
本文是51RPA中文社区原创文章。发布者:RPA小当家,转载请注明出处:https://www.51rpa.net/rpanews/3448.html